Multiview Algorithm(Co-Training)
Multiview Algorithm(Co-training)
보통 기업과 같은 조직에서 특정 프로젝트나 업무를 진행할 때, 종종 Taskforce를 구성하곤 합니다. Taskforce란 전략팀, 진행팀, 시스템전문가, 디자인전문가, 경영회계팀 등 여러 분야(조직)의 전문가들을 모아서 한팀으로 구성하여 프로젝트를 진행하는것을 뜻합니다. 이는 사람마다 잘하는 분야가 다르며, 프로젝트에서 여러 분야의 전문성이 요구될때 각자 잘하는 부분에서 능력을 발휘할 수 있게 하기 위함입니다. 즉 개개인별로 잘하는 부분을 취합하여 프로젝트를 원활히 진행하고 보다 나은 성과를 내고자 하는 개념입니다.
이러한 개념을 사람이 아닌 알고리즘에 확장하여 semi supervised learning에 활용하는것이 Multiview algorithm(Co-training)의 기본 개념입니다. Semi supervised learning에서는 레이블 되지않은 데이터(unlabeled data)에 대해 어떠한 label을 부여할 것인가가 중요합니다. Multiview algorithm에서는 이를 단일 알고리즘이 아닌, 여러 방법론들의 좋은 결과를 취합하여 데이터의 labeling에 활용하고자 합니다.
예를 들어 컴퓨터를 구분하는데 있어서, 컴퓨터의 사진을 가지고도 분류가 가능하며, 컴퓨터의 스펙을 가지고도 분류가 가능합니다. 이때 컴퓨터의 사진을 나타내는 데이터 셋과, 스펙이 적힌 데이터셋은 거의 독립적인 변수셋이라고 볼 수 있으며 이 각각의 데이터셋과 모델을 통해 좋은 결과를 취합하고자 하는것이Multiview 알고리즘입니다.
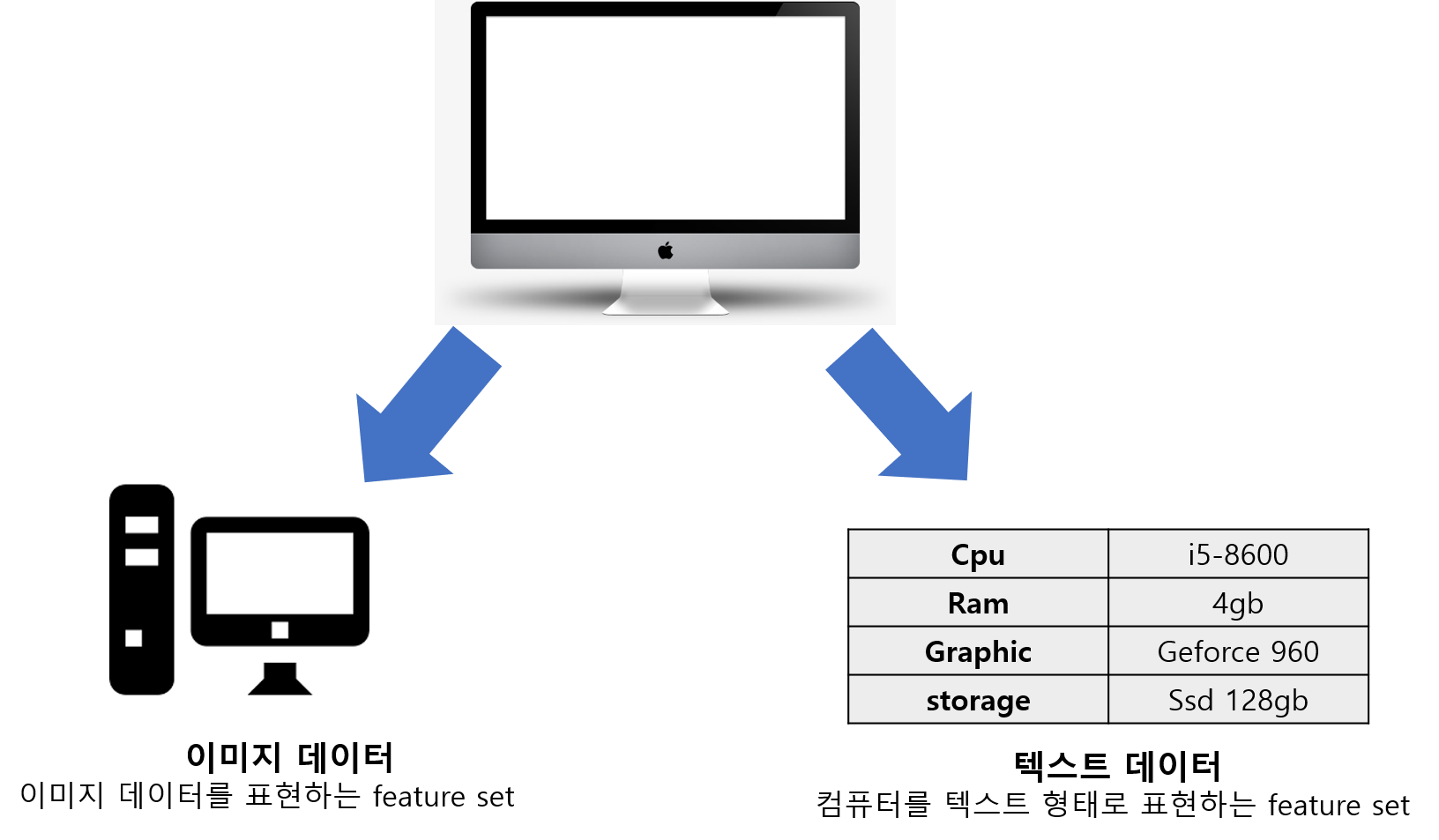
Multiview 알고리즘
Multiview 알고리즘에서는 데이터를 표현함에있어 최대한 독립적인 feature set이 필요합니다. 가령 위에서 예를든 컴퓨터를 구분함에 있어, 이미지 데이터셋들과 스펙을 알려주는 텍스트 데이터셋과 같이 전혀 상이한 특성을 가진 데이터셋이 있다면 가장 좋습니다. 하지만 이러한 여러개의 데이터셋을 얻는것은 쉽지 않습니다. 만약 한 데이터셋만 주어질 경우에도 Multiview algorithm을 활용하고자한다면, 하나의 데이터를 변수군에 따라 클러스터링하는 작업이 필요합니다. 각 데이터들을 유사성이 높은 변수들(inner correlation)이 높고 데이터셋간의 유사성은 낮은 먼저 여러개의 알고리즘을 활용하기 위해서 데이터의 변수들을 최대한 독립적인 set으로 나눕니다. D(x) = x(1), x(2), x(3)…x(n) ( 이때 n개의 split된 데이터셋에 대해서는 n개의 모델이 필요함 )
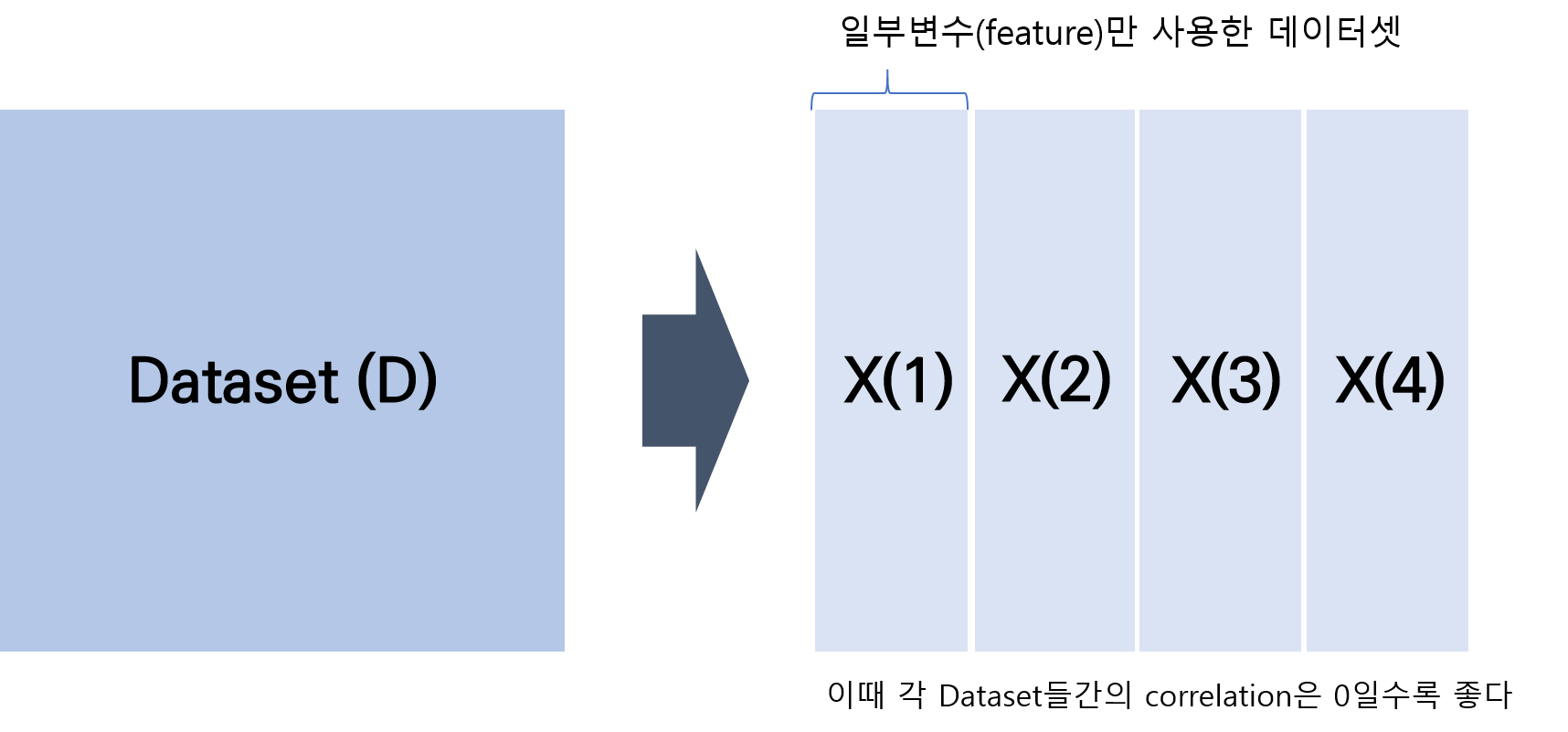
각 sub dataset을 학습하기 위한 모델들은 다 같은 모델일 필요는 없으며, 해당 데이터셋에 가장 적합한 모델을 선정하여야합니다. 가령 split된 데이터가 텍스트 데이터와 같은 sparse한 형태를 지닌 데이터는 TF-IDF등의 모델을 사용하고, 이미지 데이터의 경우 convolution neural network 등을 사용하면 좋습니다.
각 학습된 알고리즘들이 내놓은 결과값중 신뢰도(confidence level)높은 예측값들은 다른 데이터들의 label된 학습데이터로 활용이 가능합니다. 이때 신뢰도를 측정하는 방법으로 인공신경망의 경우는 accuracy를 대표적으로 활용가능하고, Naive Bayesian모델의 경우 모델 내부의 신뢰도는 Entropy, 모델간의 신뢰도는 Training error등의 지표가 사용가능합니다.
신뢰도가 높게 도출된 unlabeled 데이터의 예측값들은 해당 label을 사용하고 다른 모델의 학습데이터로 다시 활용됩니다.
위의 과정을 반복하여 최종적으로 unlabeled된 데이터들의 label을 얻을 수 있다는 것이 Multiview algorithm입니다.
python 코드를 통한 실습
실제 구체적인 예시로 데이터셋 중 많이 사용되는 iris데이터을 바탕으로 multiview 알고리즘을 사용해보았습니다. 본 데이터는 13개의 featuere와 174개의 instance로 이루어져 있습니다. 이때 원 데이터에는 모든 labeling이 되어있지만, 본 알고리즘의 의의를 위해 일부 data에 대한 label만 사용하고 나머지 개는 unlabeled data로 가정하였습니다. 따라서 174개중 90개만 labeling되어있다 생각하고 training 데이터로 활용하였습니다.
- Multiview 생성 : labeling된 데이터를 총 개의 feature를 2개의 cluster로 구분하여 2개의 데이터셋으로 나누었습니다.
- 각 모델생성(kneighborsclassifier, SVM) 후 레이블 되지 않은 데이터의 레이블 예측
- 예측된 데이터들중 신뢰도가 높은 레이블들을 다른 모델의 학습데이터로 활용( 본 모형에서는 둘의 결과값이 같은 값을 레이블로 인정하였습니다)
- iteration을 반복하여 모든 label 획득( 본 모형에서는 2번의 iteration만 진행하였습니다)
다음은 이를 구현한 파이썬 코드입니다
import numpy as np
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.cluster import FeatureAgglomeration
data = load_wine()
x = data.data
y = data.target
x_trans = x.transpose()
x_corr=np.corrcoef(x_trans)
xcorr_table = pd.DataFrame(data=x_corr)
xcorr_table
위의 과정을 통해 도출된 correlation coeficient matrix를 통해 상관관계가 낮은 2개의 cluster set를 구성하였습니다 set1 : 2,3,5,6,10,13 set2 : 1,4,7,8,9,11,12 이렇게 구성한 두 데이터셋을 토대로 2개의 모델(kneighborsclassifier, SVM)을 만든후 각각 학습하여, label을 생성하였습니다. 검증과정( 본 모형에서는 두 모델의 결과가 같은 값을 레이블로 인정하였습니다 )을 거친 후 label을 도출후 이를 다시 학습데이터로 활용하여 모든 레이블링이 완료될때까지 반복합니다
from sklearn.utils import shuffle
x, y = shuffle(x, y, random_state=0)
np.shape(x[:,1])
x[:,1:2]
np.shape(x[:,1:2])
# 위의 correlation matrix를 바탕으로
# 2개의 서로 다른 feature를 가진 데이터셋 구축
x1 = np.hstack((x[:,1:3],x[:,4:6],x[:,9:10],x[:,12:13]))
x2 = np.hstack((x[:,0:1],x[:,3:4],x[:,6:9],x[:,10:12]))
x1_train = x1[0:90,:]
x2_train = x2[0:90,:]
y_train = y[0:90]
x1_test =x1[90:,:]
x2_test =x2[90:,:]
y_test =y[90:] # 본 모형에서는 이 데이터값은 모르는것으로 합니다 (unlabled data)
# 모델 1 Keighborsclassifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x1_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=20, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
y_predict1 = knn.predict(x1_test)
# 모델 2 SVM
from sklearn import svm
svc = svm.SVC(kernel='linear')
svc.fit(x2_train, y_train)
y_predict2 = svc.predict(x2_test)
# 현재 모델에서는 Entropy라든지의 결과의 신뢰도를 측정이 어려워서 우선은 둘의 정답이 일치하는 것을 label로 인정하는 방법을 사용합니다.
y_estimate =[]
for i in range(len(y_test)):
if y_predict1[i]==y_predict2[i]:
y_estimate.append(y_predict1[i])
else:
y_estimate.append("unknown")
print(y_estimate)
# 한번의 iteration을 통해 y labeling 값 도출
ny_test=[]
check_ind=0
for i in range(len(y_test)):
if y_estimate[i]!="unknown":
x1_train = np.vstack((x1_train,x1_test[i:i+1,:]))
x2_train = np.vstack((x2_train,x2_test[i:i+1,:]))
res = np.reshape([y_estimate[i]],(1,1))
res_y =np.reshape(y_train,(len(y_train),1))
y_train = np.vstack((res_y,res))
else:
if check_ind ==0:
nx1_test= x1_test[i:i+1,:]
nx2_test= x2_test[i:i+1,:]
check_ind =1
nx1_test = np.vstack((nx1_test,x1_test[i:i+1,:]))
nx2_test = np.vstack((nx2_test,x2_test[i:i+1,:]))
ny_test.append(y_estimate[i])
print(np.shape(x1_train))
print(np.shape(y_train))
# 2번째 iteration
# 모델 1 Keighborsclassifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x1_train, y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=20, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights='uniform')
y_predict1 = knn.predict(nx1_test)
print(y_predict1)
# 모델 2 SVM
from sklearn import svm
svc = svm.SVC(kernel='linear')
svc.fit(x2_train, y_train)
y_predict2 = svc.predict(nx2_test)
print(y_predict2)
# 현재 모델에서는 Entropy라든지의 결과의 신뢰도를 측정이 어려워서 우선은 둘의 정답이 일치하는 것을 label로 인정하는 방법을 사용합니다.
y_estimate2 =[]
for i in range(len(ny_test)):
if y_predict1[i]==y_predict2[i]:
y_estimate2.append(y_predict1[i])
else:
y_estimate2.append("unknown")
print(y_estimate2)
# 두번의 iteration을 통해 y labeling 값 도출
사실 Mulitview Algorithm의 개념자체는 간단합니다. 하지만 하나의 데이터셋으로부터 독립적인 하위 데이터셋들을 생성하고 그에 맞는 모델들을 각각 구성하는 방법이 본 알고리즘의 핵심이라 할 수 있습니다. 따라서 데이터를 다각적으로 바라볼 수 있는 능력이 필요로합니다.
본 포스트는 고려대학교 강필성 교수님의 강의자료를 바탕으로 제작되었습니다.